

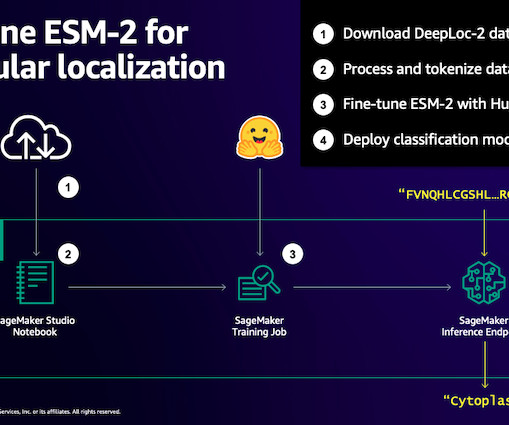
Efficiently fine-tune the ESM-2 protein language model with Amazon SageMaker
AWS Machine Learning
MARCH 6, 2024
Similarly, pLMs are pre-trained on large protein sequence databases using unlabeled, self-supervised learning. This means that it can take a long time to train them to sufficient accuracy. Long training times, plus large instances, equals high cost, which can put this work out of reach for many researchers.















































Let's personalize your content