

Customize Amazon Textract with business-specific documents using Custom Queries
AWS Machine Learning
NOVEMBER 6, 2023
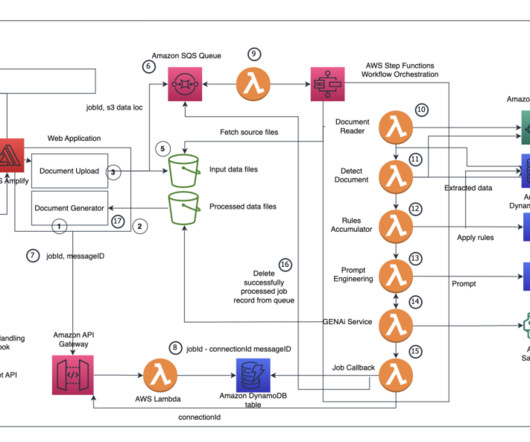
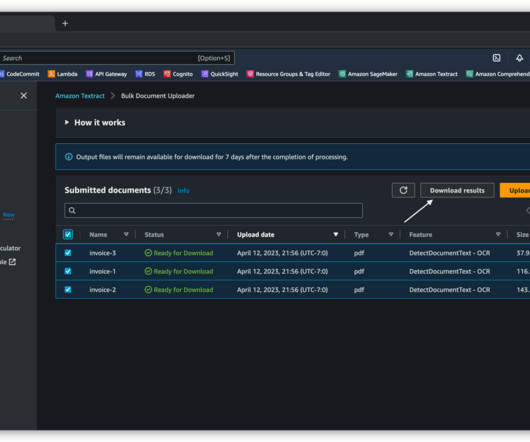
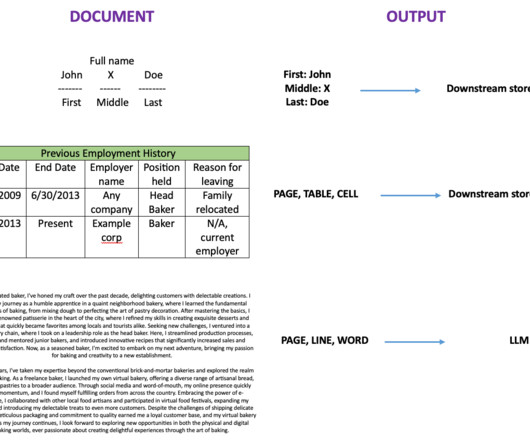
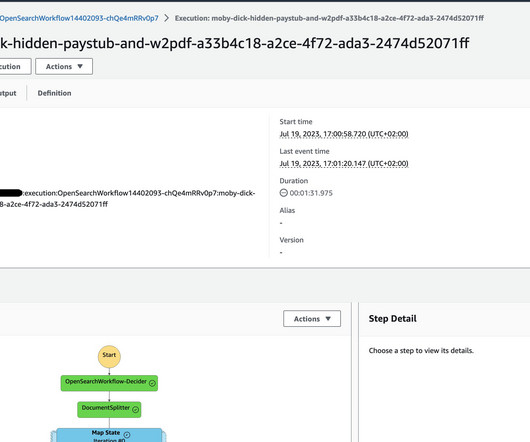
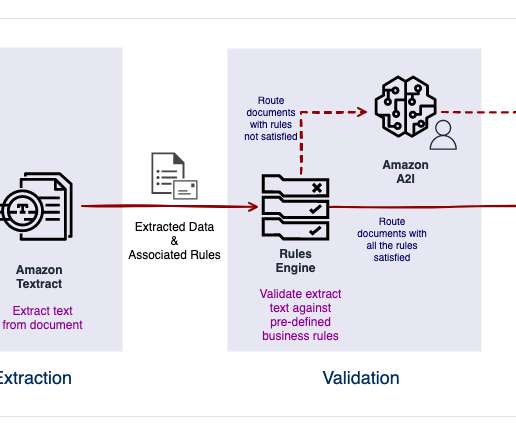
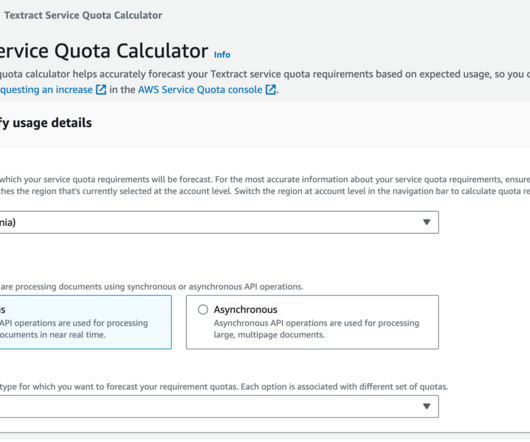
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. personal or cashier’s checks), financial institution and country (e.g.,
































Let's personalize your content