

Knowledge Bases for Amazon Bedrock now supports custom prompts for the RetrieveAndGenerate API and configuration of the maximum number of retrieved results
AWS Machine Learning
APRIL 9, 2024
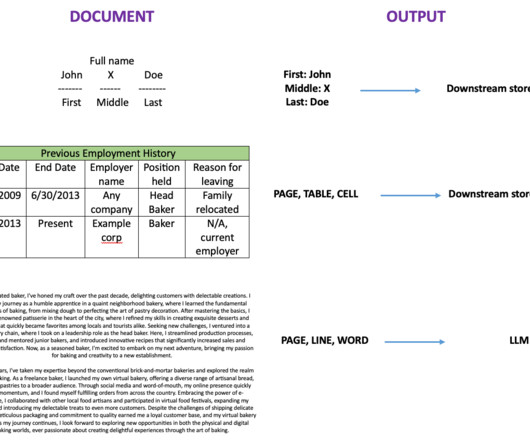
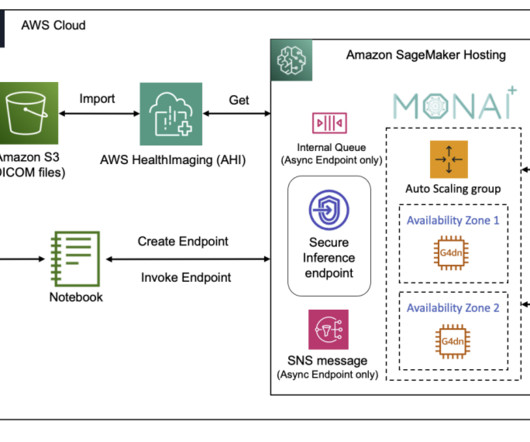
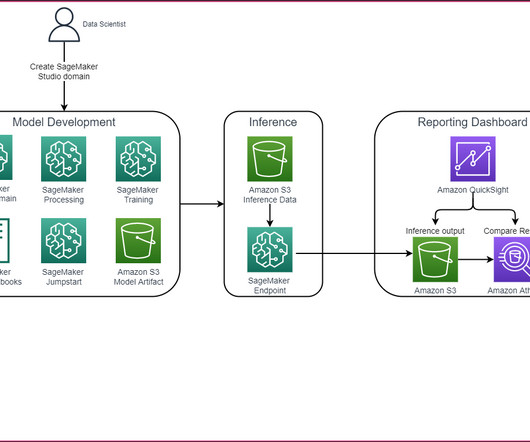
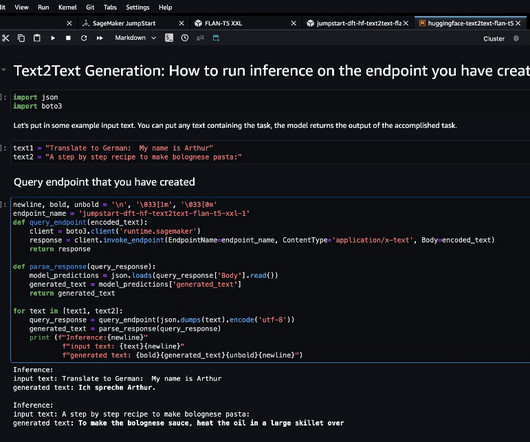
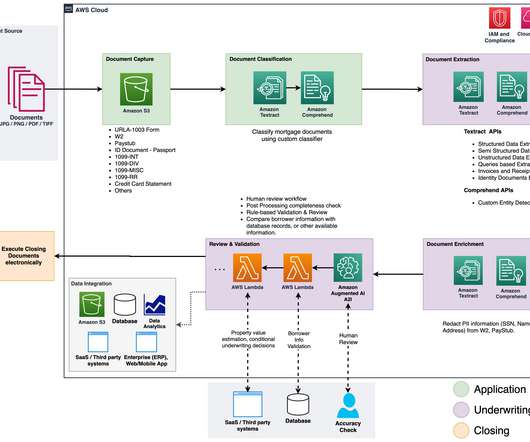
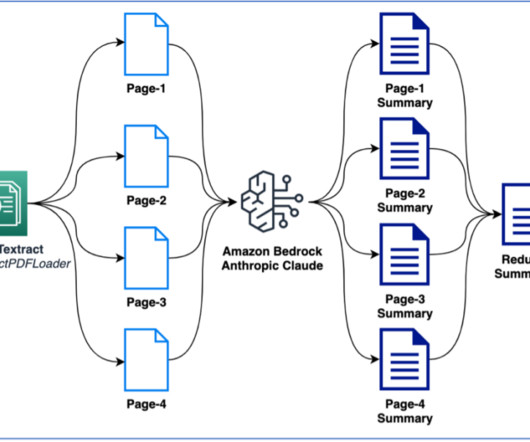
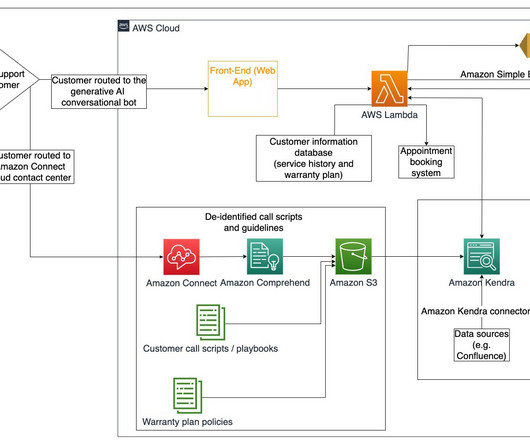
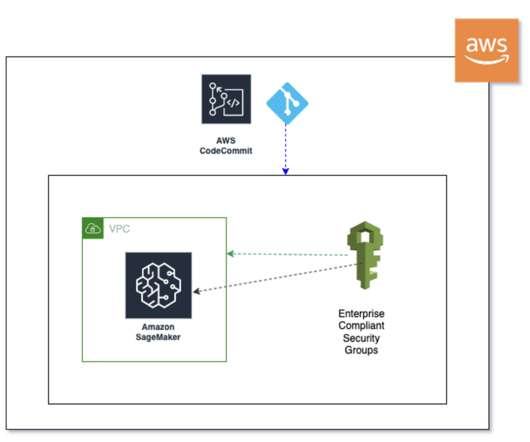
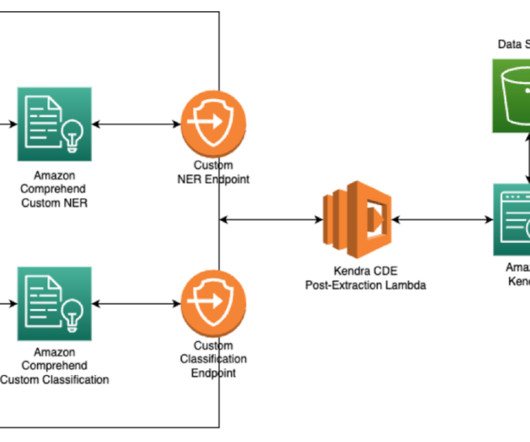
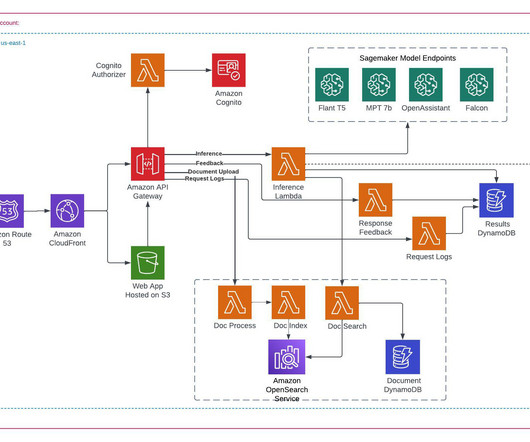
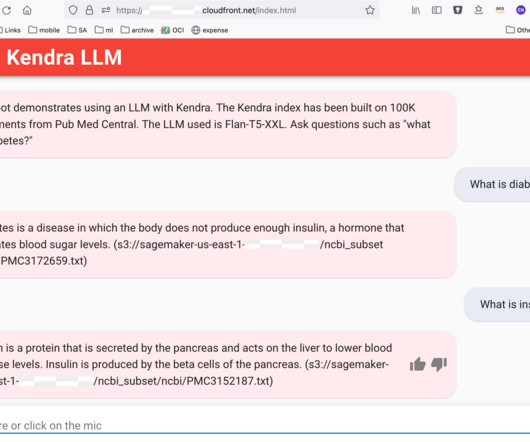
In this post, we discuss two new features of Knowledge Bases for Amazon Bedrock specific to the RetrieveAndGenerate API: configuring the maximum number of results and creating custom prompts with a knowledge base prompt template. We used Amazon 10K document for 2023 as the source data for creating the knowledge base.





























Let's personalize your content