
Build a secure enterprise application with Generative AI and RAG using Amazon SageMaker JumpStart
AWS Machine Learning
SEPTEMBER 6, 2023
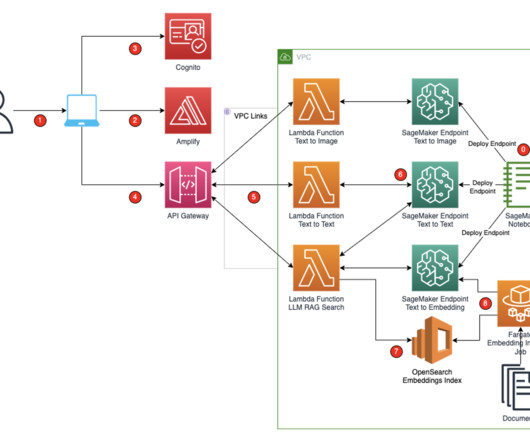
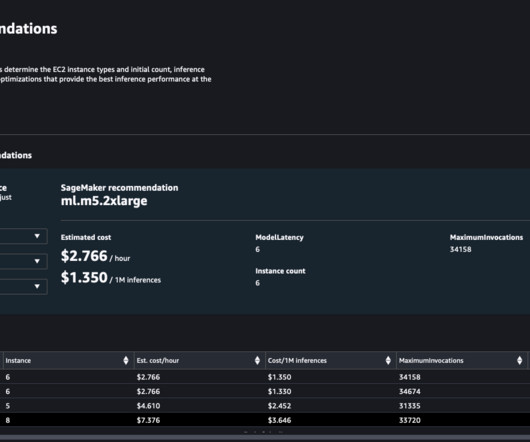
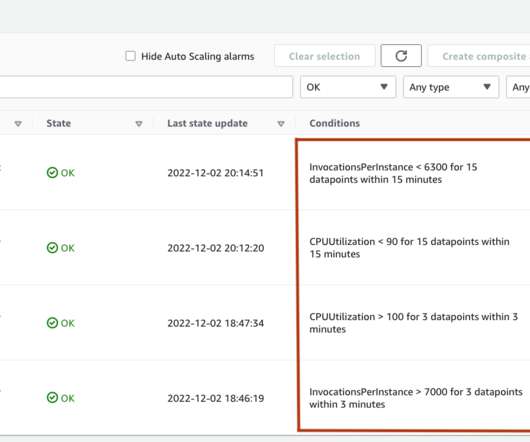
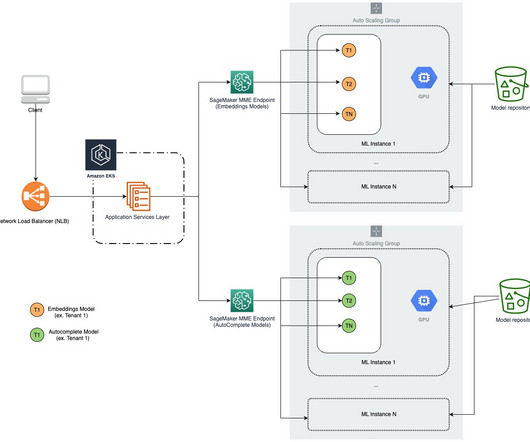
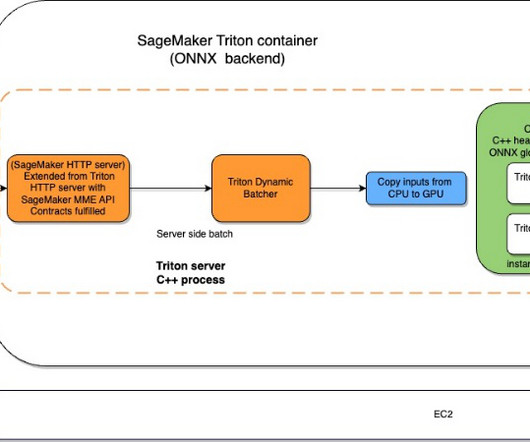
In this post, we build a secure enterprise application using AWS Amplify that invokes an Amazon SageMaker JumpStart foundation model, Amazon SageMaker endpoints, and Amazon OpenSearch Service to explain how to create text-to-text or text-to-image and Retrieval Augmented Generation (RAG). You access the React application from your computer.



































Let's personalize your content