
Configure an AWS DeepRacer environment for training and log analysis using the AWS CDK
AWS Machine Learning
FEBRUARY 13, 2023
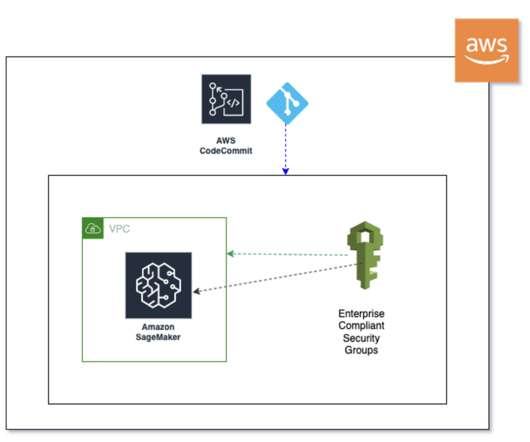
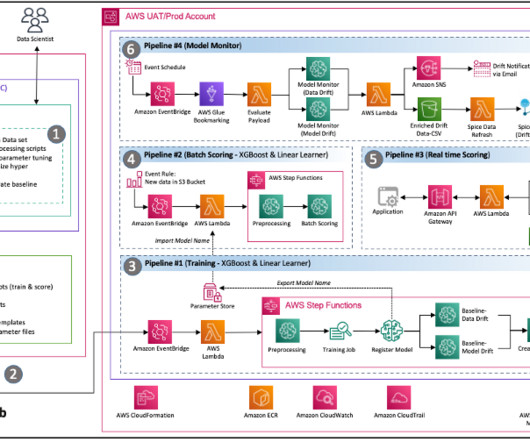
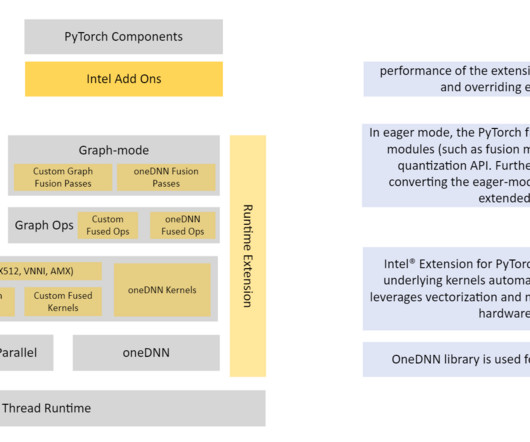
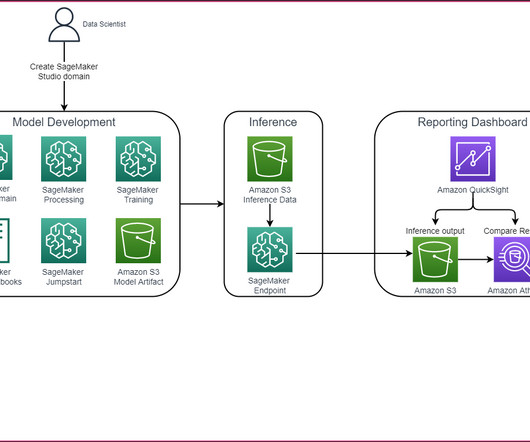
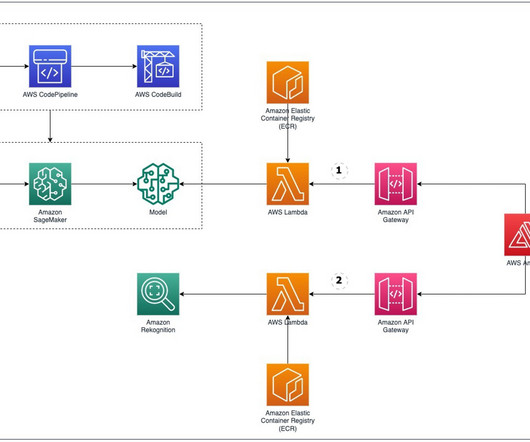
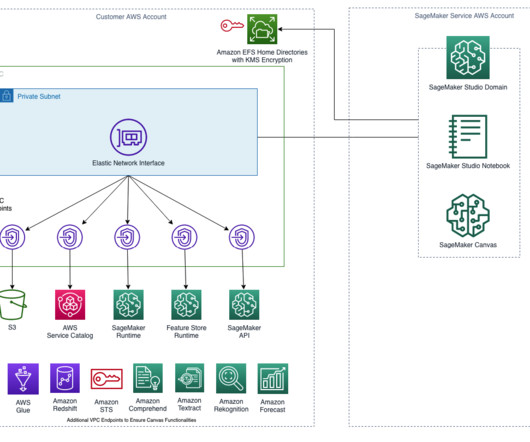
In this post, we enable the provisioning of different components required for performing log analysis using Amazon SageMaker on AWS DeepRacer via AWS CDK constructs. This is where advanced log analysis comes into play. Make sure you have the credentials and permissions to deploy the AWS CDK stack into your account.






























Let's personalize your content