
Improve multi-hop reasoning in LLMs by learning from rich human feedback
AWS Machine Learning
APRIL 27, 2023
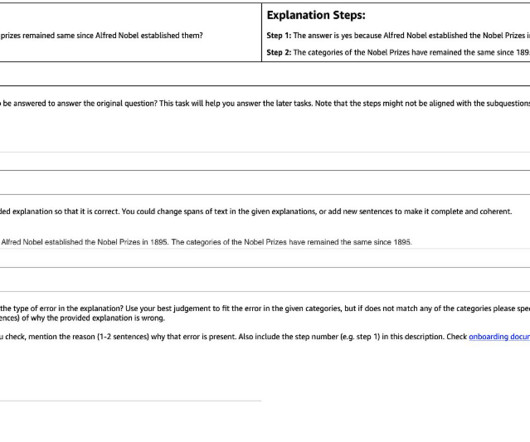
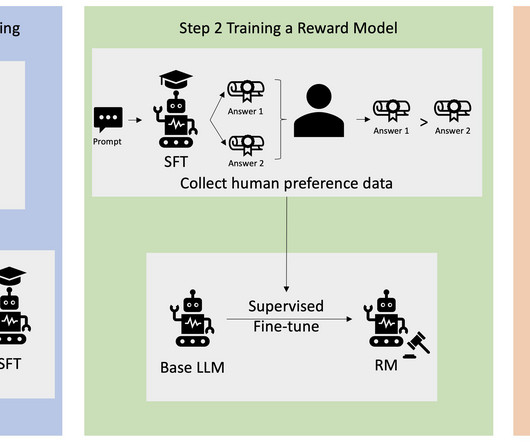
In this post, we show how to incorporate human feedback on the incorrect reasoning chains for multi-hop reasoning to improve performance on these tasks. Solution overview With the onset of large language models, the field has seen tremendous progress on various natural language processing (NLP) benchmarks.




























Let's personalize your content