
How Sportradar used the Deep Java Library to build production-scale ML platforms for increased performance and efficiency
AWS Machine Learning
APRIL 19, 2023
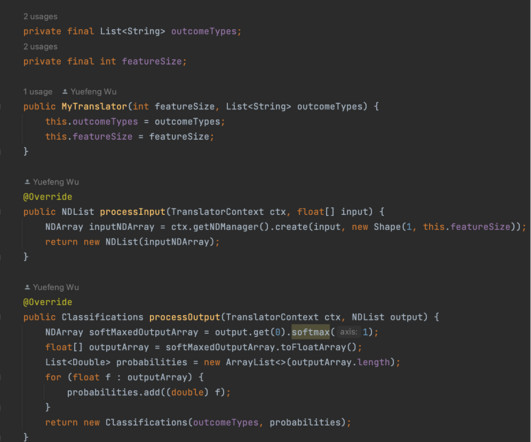
Our data scientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. Ideally, we instead want to load the model PyTorch scripts, extract the features from model input, and run model inference entirely in Java. However, a few issues came with this solution.
















Let's personalize your content