

Speed ML development using SageMaker Feature Store and Apache Iceberg offline store compaction
AWS Machine Learning
DECEMBER 21, 2022
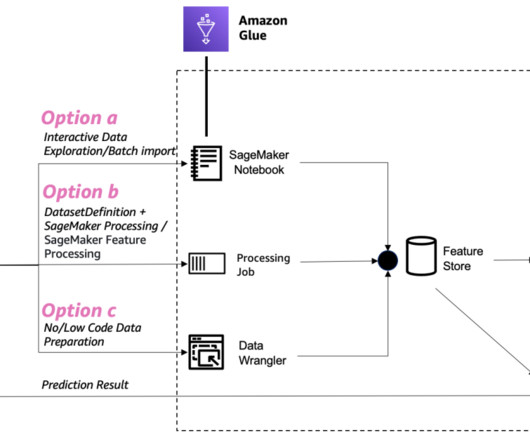
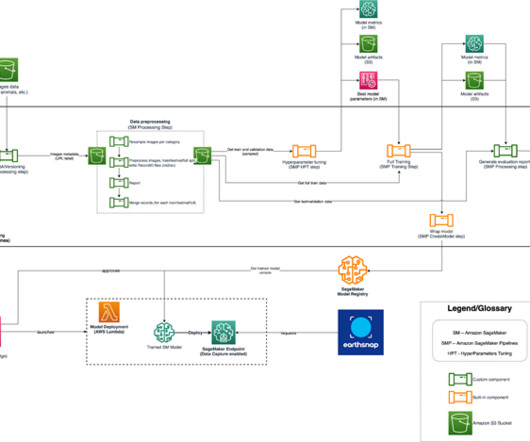
The offline store data is stored in an Amazon Simple Storage Service (Amazon S3) bucket in your AWS account. Apache Iceberg is an open table format for very large analytic datasets. To schedule the procedures, you set up an AWS Glue job using a Python shell script and create an AWS Glue job schedule. AWS Glue Job setup.
















Let's personalize your content