

Speed ML development using SageMaker Feature Store and Apache Iceberg offline store compaction
AWS Machine Learning
DECEMBER 21, 2022
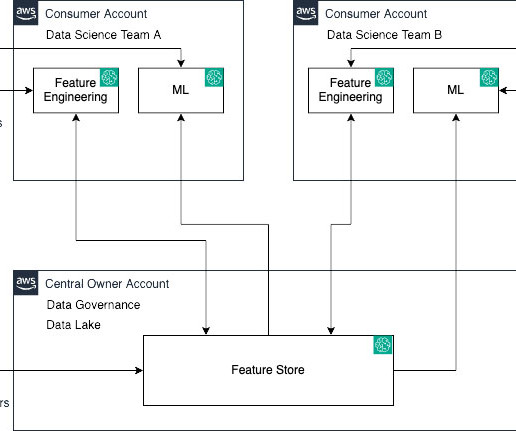
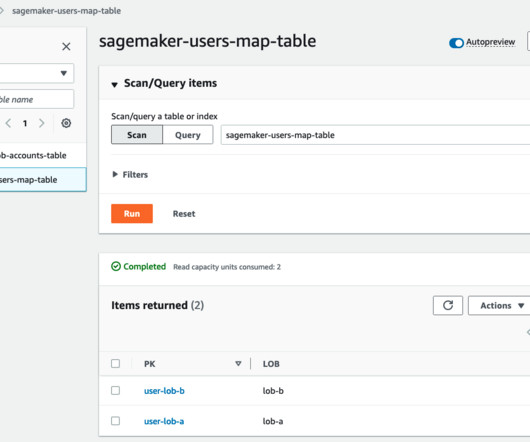
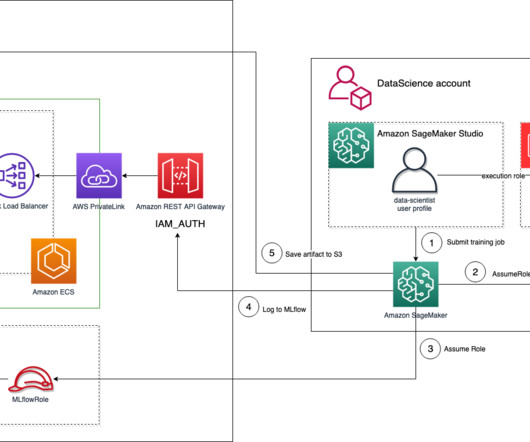
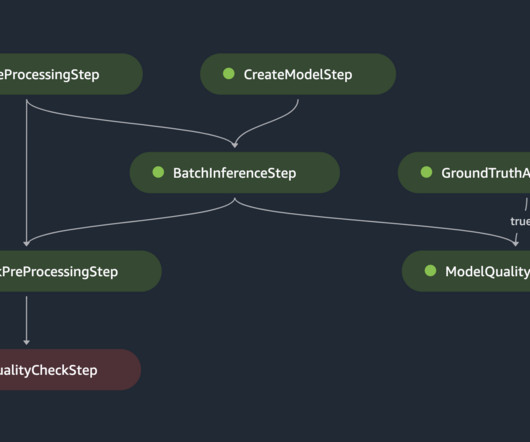
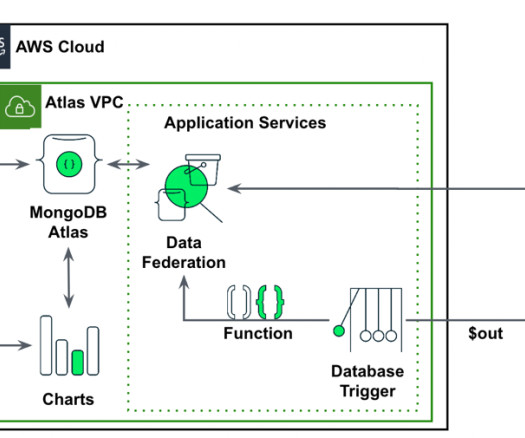
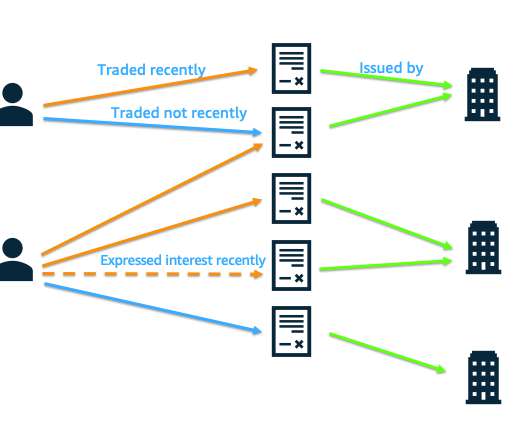
As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation.
















Let's personalize your content