
How Vericast optimized feature engineering using Amazon SageMaker Processing
AWS Machine Learning
MAY 3, 2023
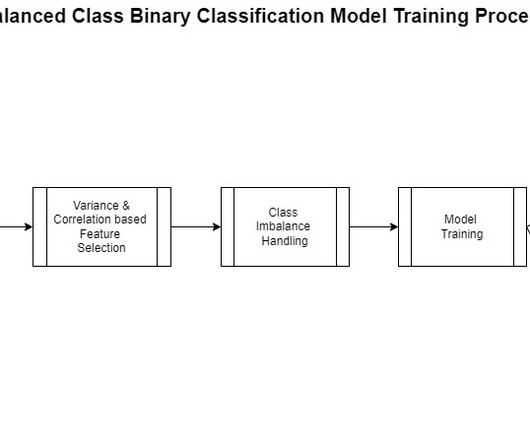
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this data preparation is feature engineering. However, generalizing feature engineering is challenging.


































Let's personalize your content