
Improving your LLMs with RLHF on Amazon SageMaker
AWS Machine Learning
SEPTEMBER 22, 2023
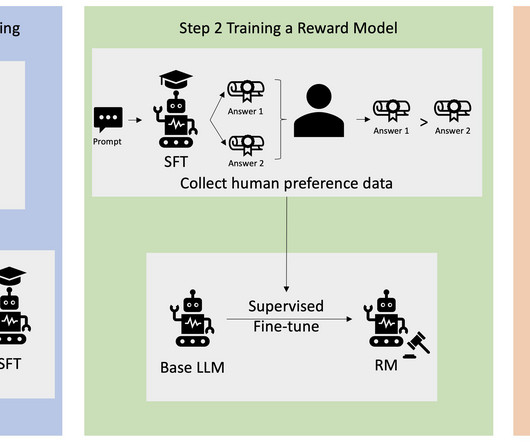
Reinforcement Learning from Human Feedback (RLHF) is recognized as the industry standard technique for ensuring large language models (LLMs) produce content that is truthful, harmless, and helpful. For the purpose of this blog post, we’re using demonstration data in the HH dataset as reported above. yaml ppo_hh.py














Let's personalize your content