
Improve multi-hop reasoning in LLMs by learning from rich human feedback
AWS Machine Learning
APRIL 27, 2023
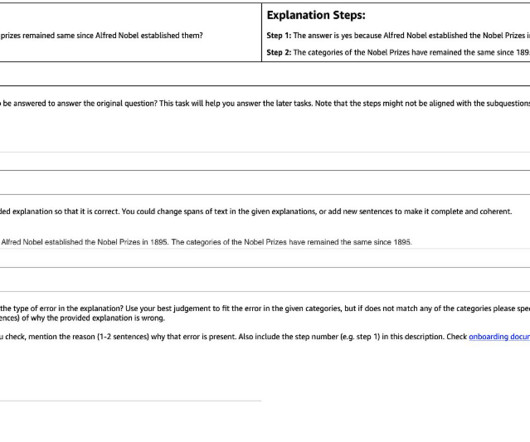
In this post, we show how to incorporate human feedback on the incorrect reasoning chains for multi-hop reasoning to improve performance on these tasks. Those confident but nonsensical explanations are even more prevalent when LLMs are trained using Reinforcement Learning from Human Feedback (RLHF), where reward hacking may occur.












Let's personalize your content