
Accelerate Amazon SageMaker inference with C6i Intel-based Amazon EC2 instances
AWS Machine Learning
MARCH 20, 2023
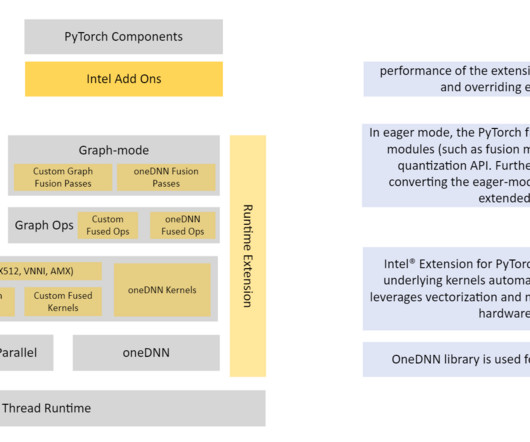
Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. In this case, you are calibrating the model with the SQuAD dataset: model.eval() conf = ipex.quantization.QuantConf(qscheme=torch.per_tensor_affine) print("Doing calibration.")













Let's personalize your content