
Accelerate Amazon SageMaker inference with C6i Intel-based Amazon EC2 instances
AWS Machine Learning
MARCH 20, 2023
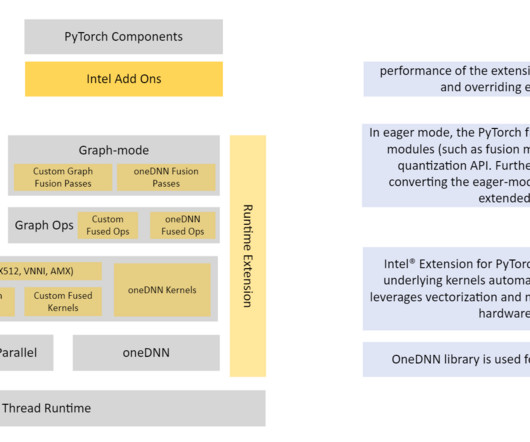
Overview of the technology EC2 C6i instances are powered by third-generation Intel Xeon Scalable processors (also called Ice Lake) with an all-core turbo frequency of 3.5 Refer to the appendix for instance details and benchmark data. Quantizing the model in PyTorch is possible with a few APIs from Intel PyTorch extensions.











Let's personalize your content