
Achieve rapid time-to-value business outcomes with faster ML model training using Amazon SageMaker Canvas
AWS Machine Learning
MARCH 3, 2023
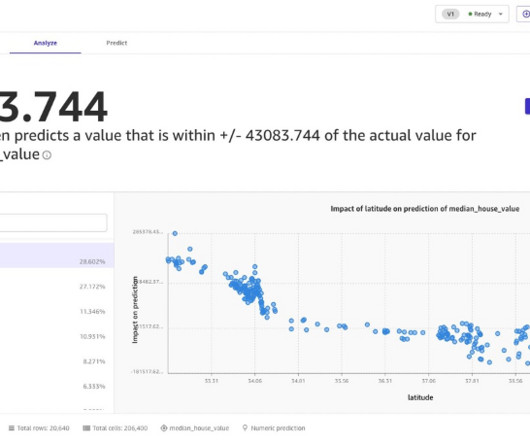
We estimated these numbers by running benchmark tests on different dataset sizes from 0.5 Under the hood, SageMaker Canvas uses multiple AutoML technologies to automatically build the best ML models for your data. His knowledge ranges from application architecture to big data, analytics, and machine learning.













Let's personalize your content