
Accelerate Amazon SageMaker inference with C6i Intel-based Amazon EC2 instances
AWS Machine Learning
MARCH 20, 2023
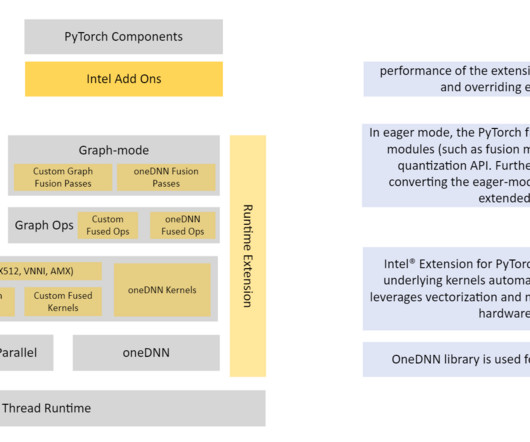
Refer to the appendix for instance details and benchmark data. Import intel extensions for PyTorch to help with quantization and optimization and import torch for array manipulations: import intel_extension_for_pytorch as ipex import torch Apply model calibration for 100 iterations. times greater with INT8 quantization.











Let's personalize your content