
Benchmark and optimize endpoint deployment in Amazon SageMaker JumpStart
AWS Machine Learning
JANUARY 29, 2024
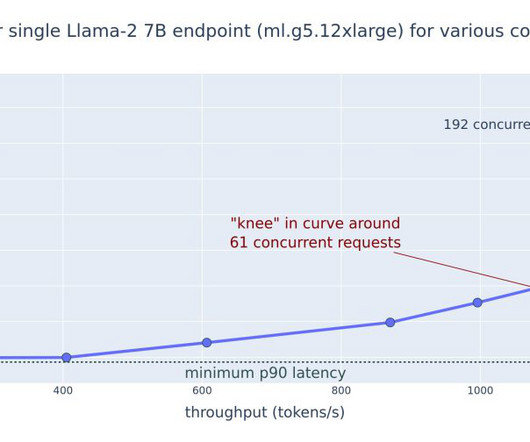
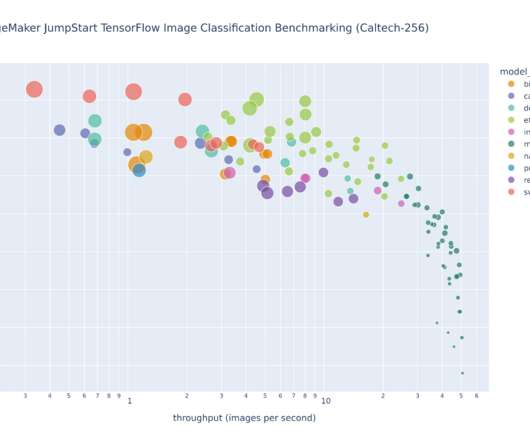
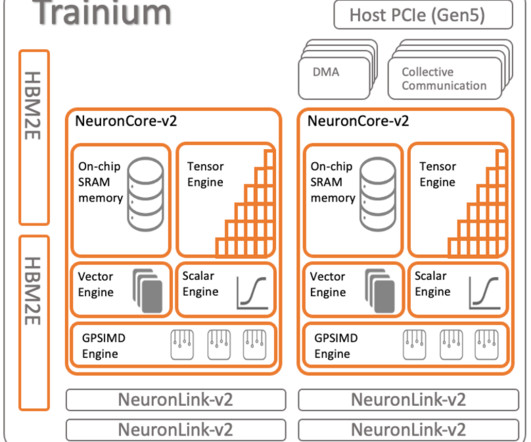
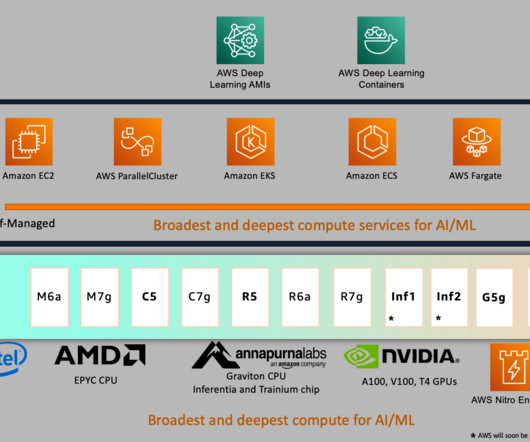
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.

































Let's personalize your content