


Enable faster training with Amazon SageMaker data parallel library
AWS Machine Learning
DECEMBER 5, 2023
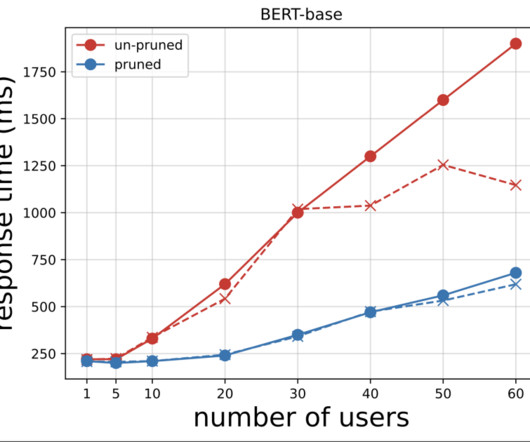
EFA is AWS’s low-latency and high-throughput network solution, and an all-to-all pattern for inter-node network communication is more tailored to the characteristics of EFA and AWS’ network infrastructure by requiring fewer packet hops compared to NCCL’s ring or tree communication pattern.

















Let's personalize your content