

Use RAG for drug discovery with Knowledge Bases for Amazon Bedrock
AWS Machine Learning
FEBRUARY 29, 2024
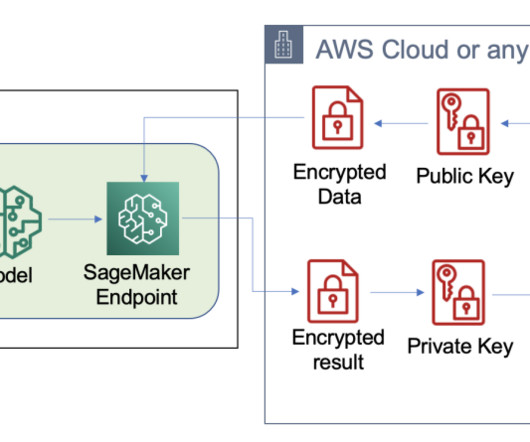
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs).














Let's personalize your content