AWS Machine Learning Blog
How Mantium achieves low-latency GPT-J inference with DeepSpeed on Amazon SageMaker
Mantium is a global cloud platform provider for building AI applications and managing them at scale. Mantium’s end-to-end development platform enables enterprises and businesses of all sizes to build AI applications and automation faster and easier than what has been traditionally possible. With Mantium, technical and non-technical teams can prototype, develop, test, and deploy AI applications, all with a low-code approach. Through automatic logging, monitoring, and safety features, Mantium also releases software and DevOps engineers from spending their time reinventing the wheel. At a high level, Mantium delivers:
- State-of-the-art AI – Experiment and develop with an extensive selection of open-source and private large language models with a simple UI or API.
- AI process automation – Easily build AI-driven applications with a growing library of integrations and Mantium’s graphical AI Builder.
- Rapid deployment – Shorten the production timeline from months to weeks or even days with one-click deployment. This feature turns AI applications into shareable web apps with one click.
- Safety and regulation – Ensure safety and compliance with governance policies and support for human-in-the-loop processes.
With the Mantium AI Builder, you can develop sophisticated workflows that integrate external APIs, logic operations, and AI models. The following screenshot shows an example of the Mantium AI app, which chains together a Twilio input, governance policy, AI block (which can rely on an open-source model like GPT-J) and Twilio output.
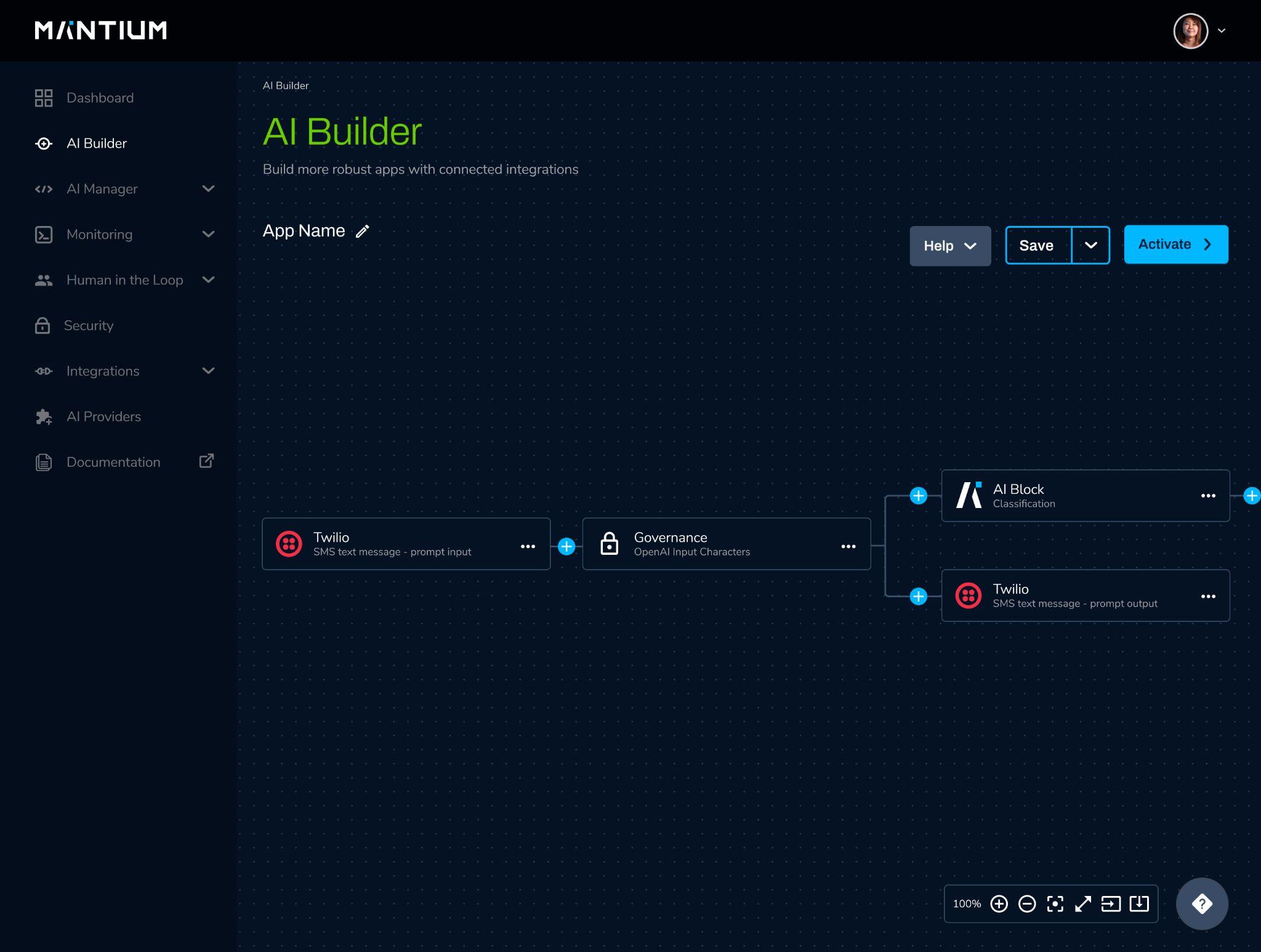
To support this app, Mantium provides comprehensive and uniform access to not only model APIs from AI providers like Open AI, Co:here, and AI21, but also state-of-the-art open source models. At Mantium, we believe that anyone should be able to build modern AI applications that they own, end-to-end, and we support this by providing no-code and low-code access to performance-optimized open-source models.
For example, one of Mantium’s core open-source models is GPT-J, a state-of-the-art natural language processing (NLP) model developed by EleutherAI. With 6 billion parameters, GPT-J is one of the largest and best-performing open-source text generation models. Mantium users can integrate GPT-J into their AI applications via Mantium’s AI Builder. In the case of GPT-J, this involves specifying a prompt (a natural language representation of what the model should do) and configuring some optional parameters.
For example, the following screenshot shows an abbreviated demonstration of a sentiment analysis prompt that produces explanations and sentiment predictions. In this example, the author wrote that the “food was wonderful” and that their “service was extraordinary.” Therefore, this text expresses positive sentiment.

However, one challenge with open-source models is that they’re rarely designed for production-grade performance. In the case of large models like GPT-J, this can make production deployment impractical and even infeasible, depending on the use case.
To ensure that our users have access to best-in-class performance, we’re always looking for ways to decrease the latency of our core models. In this post, we describe the results of an inference optimization experiment in which we use DeepSpeed’s inference engine to increase GPT-J’s inference speed by approximately 116%. We also describe how we have deployed the Hugging Face Transformers implementation of GPT-J with DeepSpeed in our Amazon SageMaker inference endpoints.
Overview of the GPT-J model
GPT-J is a generative pretrained (GPT) language model and, in terms of its architecture, it’s comparable to popular, private, large language models like Open AI’s GPT-3. As noted earlier, it consists of approximately 6 billion parameters and 28 layers, which consist of a feedforward block and a self-attention block. When it was first released, GPT-J was one of the first large language models to use rotary embeddings, a new position encoding strategy that unifies absolute and relative position encoders. It also employs an innovative parallelization strategy where dense and feedforward layers are combined in a single layer, which minimizes communication overhead.
Although GPT-J might not quite qualify as large by today’s standards—large models typically consist of more than 100 billion parameters—it’s still impressively performant, and with some prompt engineering or minimal fine-tuning, you can use it to solve many problems. Furthermore, its relatively modest size means that you can deploy it more rapidly and at a much lower cost than larger models.
That said, GPT-J is still pretty big. For example, training GPT-J in FP32 with full weight updates and the Adam optimizer requires over 200 GB memory: 24 GB for the model parameters, 24 GB for the gradients, 24 GB for Adam’s squared gradients, 24 GB for the optimizer states, and the additional memory requirements for loading training batches and storing activations. Of course, training in FP16 reduces these memory requirements almost by half, but a memory footprint of over 100 GB still necessitates innovative training strategies. For instance, in collaboration with SageMaker, Mantium’s NLP team developed a workflow for training (fine-tuning) GPT-J using the SageMaker distributed model parallel library.
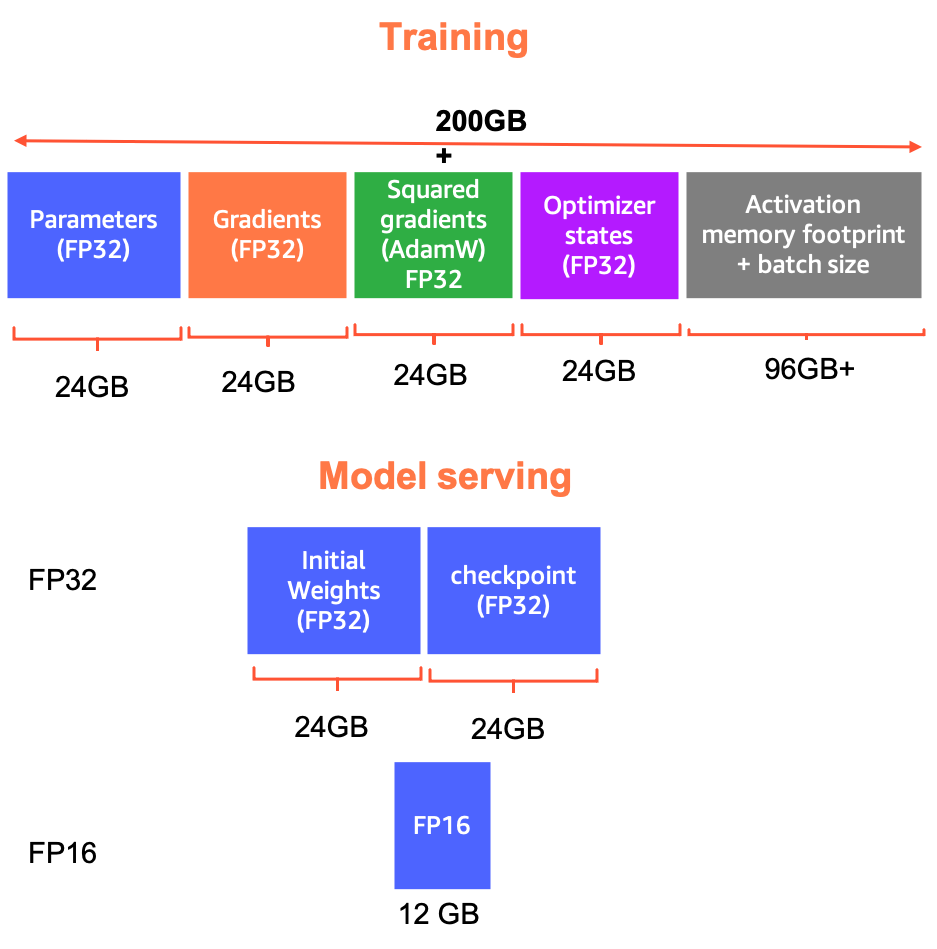
In contrast, serving GPT-J for inference has much lower memory requirements—in FP16, model weights occupy less than 13 GB, which means that inference can easily be conducted on a single 16 GB GPU. However, inference with out-of-the-box implementations of GPT-J, such as the Hugging Face Transformers implementation that we use, is relatively slow. To support use cases that require highly responsive text-generation, we’ve focused on reducing GPT-J’s inference latency.
Response latency challenges of GPT-J
Response latency is a core obstacle for the generative pretrained transformers (GPTs) such as GPT-J that power modern text generation. GPT models generate text through sequences of inference steps. At each inference step, the model is given text as input, and, conditional on this input, it samples a word from its vocabulary to append to the text. For example, given the sequence of tokens “I need an umbrella because it’s,” a high-likelihood next token might be “raining.” However, it could also be “sunny” or “bound,” which could be the first step toward a text sequence like “I need an umbrella because it’s bound to start raining.”
Scenarios like this raise some interesting challenges for deploying GPT models because real-world use cases might involve tens, hundreds, or even thousands of inference steps. For example, generating a 1,000-token response requires 1,000 inference steps! Accordingly, although a model might offer inference speeds that seem fast enough in isolation, it’s easy for latency to reach untenable levels when long texts are generated. We observed an average latency of 280 milliseconds per inference step on a V100 GPU. This might seem fast for a 6.7 billion parameter model, but with such latencies, it takes approximately 30 seconds to generate a 500-token response, which isn’t ideal from a user experience perspective.
Optimizing inference speeds with DeepSpeed Inference
DeepSpeed is an open-source deep-learning optimization library developed by Microsoft. Although it primarily focuses on optimizing of training large models, DeepSpeed also provides an inference optimization framework that supports a select set of models, including BERT, Megatron, GPT-Neo, GPT2, and GPT-J. DeepSpeed Inference facilitates high-performance inference with large Transformer-based architectures through a combination of model parallelism, inference-optimized CUDA kernels, and quantization.
To boost inference speed with GPT-J, we use DeepSpeed’s inference engine to inject optimized CUDA kernels into the Hugging Face Transformers GPT-J implementation.
To evaluate the speed benefits of DeepSpeed’s inference engine, we conducted a series of latency tests in which we timed GPT-J under various configurations. Specifically, we varied whether or not DeepSpeed was used, hardware, output sequence length, and input sequence length. We focused on both output and input sequence length, because they both affect inference speed. To generate an output sequence of 50 tokens, the model must perform 50 inference steps. Furthermore, the time required to perform an inference step depends on the size of the input sequence—larger inputs require more processing time. Although the effect of output sequence size is much larger than the effect of input sequence size, it’s still necessary to account for both factors.
In our experiment, we used the following design:
- DeepSpeed inference engine – On, off
- Hardware – T4 (ml.g4dn.2xlarge), V100 (ml.p3.2xlarge)
- Input sequence length – 50, 200, 500, 1000
- Output sequence length – 50, 100, 150, 200
In total, this design has 64 combinations of these four factors, and for each combination, we ran 20 latency tests. Each test was run on a pre-initialized SageMaker inference endpoint, ensuring that our latency tests reflect production times, including API exchanges and preprocessing.
Our tests demonstrate that DeepSpeed’s GPT-J inference engine is substantially faster than the baseline Hugging Face Transformers PyTorch implementation. The following figure illustrates the mean text generation latencies for GPT-J with and without DeepSpeed acceleration on ml.g4dn.2xlarge and ml.p3.2xlarge SageMaker inference endpoints.

On the ml.g4dn.2xlarge instance, which is equipped with a 16 GB NVIDIA T4 GPU, we observed a mean latency reduction of approximately 24% [Standard Deviation (SD) = 0.05]. This corresponded to an increase from a mean 12.5 (SD = 0.91) tokens per second to a mean 16.5 (SD = 2.13) tokens per second. Notably, DeepSpeed’s acceleration effect was even stronger on the ml.p3.2xlarge instance, which is equipped with an NVIDIA V100 GPU. On that hardware, we observed a 53% (SD = .07) mean latency reduction. In terms of tokens per second, this corresponded to an increase from a mean 21.9 (SD = 1.97) tokens per second to a mean 47.5 (SD = 5.8) tokens per second.
We also observed that the acceleration offered by DeepSpeed attenuated slightly on both hardware configurations as the size of the input sequences grew. However, across all conditions, inference with DeepSpeed’s GPT-J optimizations was still substantially faster than the baseline. For example, on the g4dn instance, the maximum and minimum latency reductions were 31% (input sequence size = 50) and 15% (input sequence size = 1000), respectively. And on the p3 instance, the maximum and minimum latency reductions were 62% (input sequence size = 50) and 40% (input sequence size = 1000), respectively.
Deploying GPT-J with DeepSpeed on a SageMaker inference endpoint
In addition to dramatically increasing text generation speeds for GPT-J, DeepSpeed’s inference engine is simple to integrate into a SageMaker inference endpoint. Before adding DeepSpeed to our inference stack, our endpoints were running on a custom Docker image based on an official PyTorch image. SageMaker makes it very easy to deploy custom inference endpoints, and integrating DeepSpeed was as simple as including the dependency and writing a few lines of code. The open-sourced guide to the deployment workflow to deploy GPT-J with DeepSpeed is available on GitHub.
Conclusion
Mantium is dedicated to leading innovation so that everyone can quickly build with AI. From AI-driven process automation to stringent safety and compliance settings, our complete platform provides all the tools necessary to develop and manage robust, responsible AI applications at scale and lowers the barrier to entry. SageMaker helps companies like Mantium get to market quickly.
To learn how Mantium can help you build complex AI-driven workflows for your organization, visit www.mantiumai.com.
About the authors
 Joe Hoover is a Senior Applied Scientist on Mantium’s AI R&D team. He is passionate about developing models, methods, and infrastructure that help people solve real-world problems with cutting-edge NLP systems. In his spare time, he enjoys backpacking, gardening, cooking, and hanging out with his family.
Joe Hoover is a Senior Applied Scientist on Mantium’s AI R&D team. He is passionate about developing models, methods, and infrastructure that help people solve real-world problems with cutting-edge NLP systems. In his spare time, he enjoys backpacking, gardening, cooking, and hanging out with his family.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
 Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage AI/ML for their business outcomes and design and deploy ML/AI solutions at scale.
Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage AI/ML for their business outcomes and design and deploy ML/AI solutions at scale.