
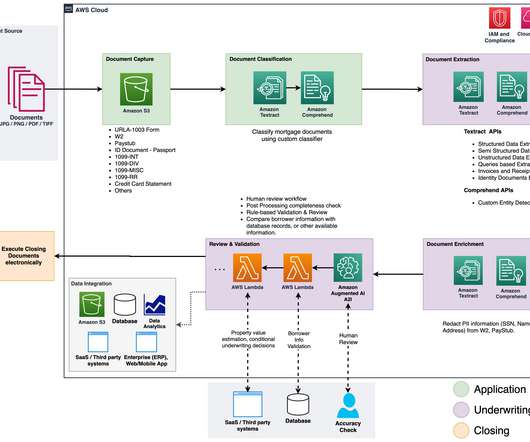
Process mortgage documents with intelligent document processing using Amazon Textract and Amazon Comprehend
AWS Machine Learning
AUGUST 26, 2022
The following is a high-level overview of the steps involved: Extract UTF-8 encoded plain text from image or PDF files using the Amazon Textract DetectDocumentText API. For structured and semi-structured documents containing forms and tables, we use the Amazon Textract AnalyzeDocument API. Train a custom classifier using the CSV file.









Let's personalize your content