
The way to understand how AI automation (i.e. bot, virtual assistant) works in customer support is to look at how humans are responding to and supporting customers.
It starts with the customer query.
You sit down and grab the next customer query in your Inbox. First thing, you read it and understand it. This is crucial. If you don’t understand it, you can’t resolve it.
 Human intelligence in customer service
Human intelligence in customer service
The understanding part is a complex process occurring in the human brain where you access almost involuntarily past knowledge about the product you’re supporting, contextual knowledge and similar queries from other customers. The more such queries you’ve resolved in the past, the easier it is to understand.
Let’s take an example with this inquiry: “We just purchased and received 3 devices, when I connect them to our WIFI or LAN they show connected. Then when you hit “Next” it says connection lost”.
Unless you know the product or you’ve seen similar issues before, it will take a while to comprehend what it means. What are those devices? What is “Next“? What does it mean to connect them to WiFi? If you’re a bit techie it might seem easy – you’ve connected your smartphone or laptop to WiFi many times before. But this is exactly what contextual knowledge is: something learned from past experience and applied in new but similar context.
Let’s look at another query: “I have been facing issue with MAPIx actions in version 7. Whenever I tried to move or read an email by using MAPIx objects it gets stuck or it shows “connection lost” as runtime resource status”
Most people won’t be able to grasp what the issue is. It requires both advanced product knowledge and past experience. However, if you’ve resolved these kinds of issues many times before it becomes much easier. You can quickly understand what the customer is trying to achieve but he can’t.
Sometimes it is clear what the customers are saying and what the problem is, but other times you need to dig deeper. Depending on the query, you might need more information to troubleshoot the problem, find the root cause and come up with a solution. That might include a software version, account number or additional logs.
Assuming you have all the information you need, the next step is to take one or many actions that hopefully answers the question or resolves the problem. That might include one or a combination of: checking internal systems, doing something on behalf of the customer, asking the customer to do something or escalating further to other teams.
These two essential parts define any customer support interaction: first understand the customer query, then take action to resolve it. For more complex issues the sequence understand-action repeats a few times until it is eventually resolved.
Now that we decomposed how customer support works with humans in the front seat, let’s have a look at how an AI bot/assistant can do the same job.
 How machines understand human language
How machines understand human language
Same as with human agents, the first part and the most important is understanding the customer query. It is also the most difficult part to implement and where a large number of AI initiatives fail. Any Artificial Intelligence solution uses a particular set of machine learning algorithms for this purpose, called classification algorithms. The principle behind machine learning classification is very simple and somehow similar (oversimplified of course) to how humans learn: make the correct future decisions based on the knowledge you gathered from past experiences.
Here past experiences are represented by a set of examples, each example including the phrasing of what the customer is actually saying and the correct granular category his query falls into.
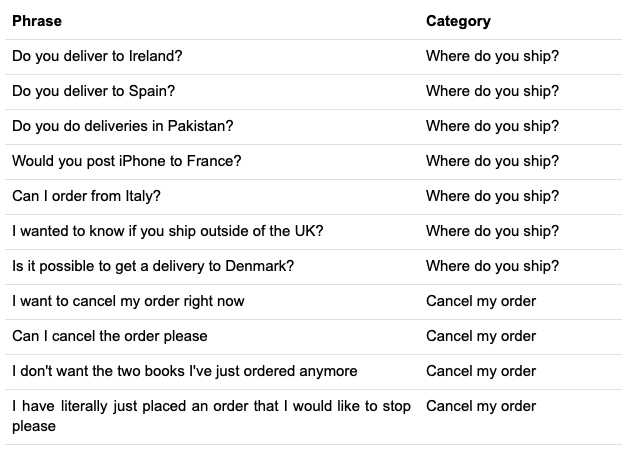 Given sufficient such examples, the classification algorithm “learns” their pattern, or how customers are usually phrasing queries in each category. Behind the scenes during “learning” the algorithm is tuning a mathematical function representing a mapping between inputs (examples) and outputs (categories).
Given sufficient such examples, the classification algorithm “learns” their pattern, or how customers are usually phrasing queries in each category. Behind the scenes during “learning” the algorithm is tuning a mathematical function representing a mapping between inputs (examples) and outputs (categories).
In machine learning jargon the list of examples is called training data and the process of learning (or tuning the function) is called training a machine learning model. After this process is completed, any future inputs that are similar to those given in the training data should be correctly classified most of the time.
Let’s take the first two examples from the list illustrated above:
- Do you deliver to Ireland?
- Do you deliver to Spain?
One can easily spot the pattern here as being: “Do you deliver to <location>”. After going through a number of such examples, the mathematical function is tuned to learn that any other similar phrases, like “Do you deliver to Denmark?“, fall into the “Where do you ship?” category.
The pattern is represented by both the list of words used but also the order in which the words appear. A change in word order often results in a change of meaning: Do you deliver to Ireland vs. You do delivery to Ireland.
The more diversified the training data is for each category the better the algorithm gets to understand future customer inquiries.
Unfortunately this is also the biggest challenge in getting an AI implementation to correctly understand what the customer is saying. Human language is naturally diverse and there are so many possible ways people ask the same question. For example when asking “where do you ship?“, a customer can actually say any of the phrases below:
- Do you deliver to Ireland?
- Would you post to France?
- Can I order from Italy?
- I wanted to know if you ship outside of the UK?
- Is it possible to get a delivery to Denmark?
and many many more. The meaning of these phrases is only one, yet they are very different to from each other.
Ideally your training data would include a number of examples from each pattern your customers might use to ask a question or mention a problem. Very hard to achieve, but possible to get close if you have access to and use phrases from past conversations between customers and agents. Just guessing what the customer might say is far from being enough, although unfortunately this is how many customer service automation projects (i.e. chatbots) begin with.
 Building your training data for AI
Building your training data for AI
We’ve seen that having access to good quality training data is essential to have your automation understand what customers are saying, but what is actually good quality? There are four dimensions to consider, in this order of importance: correctness, cleanliness, diversity and volume.
Correct data
Think of the classification algorithm used for language understanding as an approximation method. For any given category in the training examples, it approximates the ground truth of what humans think the category should be. Therefore it will always have less accurate results than the ground truth. If the ground truth is incorrect or inconsistent, the results will be the same or worse.
This is the reason why examples in the training data need to have the correct category assigned, ideally in all cases. Harder to achieve than it seems, especially if you are dealing with a large number of categories. The biggest difficulty is consistency, mostly because of the inherent ambiguities of human language. One person can assign a phrasing to a particular category, yet another person will assign a similar phrasing with the same meaning to a different category. This is highly dependent on the way your categories are defined.
Let’s take an example. You have two categories: Shipping costs (questions or complains about shipping fees) and Overcharged (customer says he was charged more than it should be). A phrasing like “What is the estimated delivery price?” would be easily considered as Shipping costs by anybody. But how about “I have been wrongly charged a shipping fee” ? Depending on the person, one can consider this phrase as being either Shipping costs or Overcharged. Even one single person can assign a phrase like this to Shipping costs at some point, yet later on assign a similar phrase with the same meaning to Overcharged.
The consistency problem can be avoided by defining all the categories rigorously in a shared document, mentioning each edge case, like the one above, to what category it should belong.
Clean data
Classification algorithms in machine learning work by picking up signals in your training data and “learning” patterns of how these signals occur. In case of customer conversations, signals are words customers use when they phrase a question. In order for the algorithm to be efficient, most of the signals (words) have to be relevant to the meaning of the question. Add words that are irrelevant, and the algorithm will pick up on the wrong signals. This is the noise you want to avoid in your training examples.
When you are getting your training data from past conversations with customers, it is easy to include noise. A ticket for example can include the phrasing of the customer question but also additional sentences and lines that are irrelevant to your categories, and most have no meaning whatsoever. Examples of these are: email signatures, addresses, disclaimers, automated messages etc. This is the reason why you can’t just take a set of conversations tagged by your agents and throw them to a machine learning algorithm. No matter how good the algorithm is, it will fail.
Make sure to avoid noise as much as possible when building your training data. Always use the shortest phrase you can get to capture the full meaning of a category.
Diverse data
We’ve seen previously that people can phrase the same question in lots of different ways. Therefore, the more different ways of saying the same thing you include in the training data, the better your automation gets to understand the question.
It is almost impossible to come up with all the variants from your own memory, no matter how experienced you are in dealing with customers. You can overcome this by getting access and using historical conversations between your customers and agents such as emails, chat transcripts or voice transcripts. Instead of trying to guess what phrase a customer might use for a question, look at what phrases they’ve been using in the past to ask the same question.
The historical data is already available in your Helpdesk. You can look for these phrases by reading the conversations there, exporting the data to Excel or using a customer support analytics and automation app that loads, indexes and tags the historical conversations, making it available for searching and exploring.
Big data
In general, the more training data you have, the better. On the other side, building up the examples in each category is a manual task and very resource intensive, so there is a limit of how much data you can get.
While high performance algorithms, like Deep Neural Networks, need a large quantity of training data to begin with, the latest generation of deep learning algorithms applied to human language makes it possible to get started with much less. Now one can use existing machine learning models that were pre-trained on a huge dataset and transfer the knowledge to a new model that requires significantly less data to train. In machine learning jargon this new set of methods is called transfer learning. Most of the natural language APIs provided by major machine learning vendors are also using some form of transfer learning to speed up the training process.
The amount of training data you need also depends on the number of categories you have. Even though you can start with as little as 10-20 examples per category it is highly likely you need at least 100 examples in each, possibly more. This is still significantly less that the first generation of deep learning methods where the requirements were in the order of thousands per category.
Focusing on having a correct, clean and diverse training data will also help your algorithm learn with fewer examples. The better quality data you have, the less volume you need.
 Conclusion
Conclusion
AI automation has great potential in helping support teams become more efficient and get better at serving their customers. In order to offload part of the work from human agents, an AI solution needs to learn how to understand what customers are asking.
This is the core of any AI automation in customer service and also the most difficult part to implement. Human language has several characteristics (variety, ambiguity, linguistic context) that makes it very hard for machines to grasp. The latest generation of machine learning technology have made incredible progress in language understanding, but still requires rigorous work to teach. By focusing on having high quality training data that is correct, varied, clean and large enough, one can turn any AI initiative into a great success.
How did you like this blog?












